Method Description
Abstract
The goal of this little article is to show the similarities between user-interface (UI) events and the receipt of MPI messages, and to develop this idea into a framework or layer that can be used to abstract complexities of Message Passing Interface (MPI) applications and so simplify their development and maintenance, and by so doing improve the throughput and decrease the runtime of the application. This method circumvents the usual problems associated with running MPI applications on heterogeneous architectures or on networked computer systems where the applications are competing for resources. Quite the goal, isn't it?
Introduction
MPI applications are computer programs that are written to run on multiple CPU or even multiple cores of a single CPU
(not restricted to a 1:1 relationship between copies of the program and cores). These programs use the Message
Passing Interface (MPI) Communications Protocol and are started by an MPI-specific command (usually
mpiexec
or
mpirun
). The MPI startup command loads the requested number of copies of the program on however many named hosts as are
known to the command. For instance, this command will start 24 copies of the
hostname
program.
mpiexec -n 24 hostname
All 24 copies of the
hostname
application may be started on the current machine, or on 24 connected CPUs; depending upon how many individual CPUs
are connected together in the system and available to the
mpiexec
command. If this is run on a single CPU with a single core, there will still be 24 copies started, but they'll run in
series.
MPI supplies every running instance with its unique identifying number and with the total number of program copies
running. These instance numbers are referred to as the rank in MPI terminology (and run from 0 up to the
number requested - the
-n
parameter) and the size in the above command (the "n" argument). It is up to the program to decide what, if
anything, to do with these numbers. The application may be written to take the problem at hand and divide the work
into as many nodes as are available, and simply do that portion of their work (based on their rank and the total
number of nodes) and then exit. While this is undoubtedly the simplest way to make use of the MPI system, it is not
necessarily the most efficient, and certainly not the only one.
In addition to the rank and total number described above, MPI allows one instance to communicate with another
instance using the MPI_send and MPI_receive methods. These communications are point-to-point rendezvous where one
instance sends a message to another instance by number. The sending node sends a message of a specific type to a
receiving node which must have the matching receive function call. The receiver may be set to receive the message
from any node in the system (a special MPI flag
MPI_ANY_SOURCE
) or from one specific node (by number).
MPI also allows one node to broadcast a message to all the other nodes with the MPI_bcast method. All the other instances rendezvous with the sender and receive a copy of the message.
There are additional MPI methods for sending messages, some of which are also blocking, and some of which are not.
The non-blocking methods include the
MPI_Isend
and
MPI_Irecv
. The difficulty with using these is the requirement for the application to periodically check to see if the message
is properly sent before destroying the outgoing message or reclaiming that memory for other purposes. This adds an
unnecessary complication to the structure and hence the maintenance of the program.
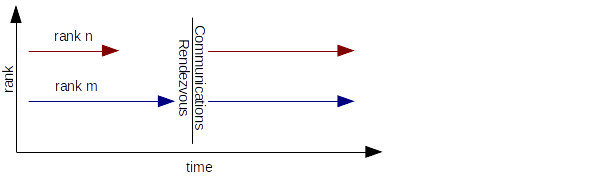
If the sender is rank n of Figure 1, and the receiver rank m, and the sender sends before the receiver has reached that particular rendezvous in the code for blocking or synchronous communications, the sending application waits until the message is delivered. If the receiver is rank m, and it reaches that part of the code before rank n sends the message, it waits until the message is delivered. In either case, this can lead to inefficiencies while nodes wait for the rendezvous to complete. The MPI alternative to synchronized communications is asynchronous, but this increases the complexity of the application, which must periodically check the status of the transmission.
Communications between instances running on different cores of one CPU are much faster than those going across the network to other instances of the application. This communications heterogeneity between separate CPUs or between cores on a single CPU is one reason why simply dividing the work across all instances and foregoing communications altogether is often preferred over synchronized communications. It also restricts the type of problem that is generally solved by using MPI in the first place: problems that can statically perform a divide and conquer approach.
UI and MPI Commonality
In UI frameworks like Qt, the application registers delegates (methods or functions) that the framework invokes when it receives events from the user, internal timers, or file system operations. When the event happens, the framework invokes the previously registered method and passes it the event information and waits for the thread of control to be returned. This is a standard architectural design principle or software pattern commonly used in Object Oriented Programming. This keeps the user application from having to check and wait for events - the framework does this. (It also means that the framework may seem to "lock-up" while the user application is doing something that takes longer than anticipated.) This approach effectively gives overall control of the execution to the framework until some previously specified event causes the framework to return control to the application - usually for termination. This is called Inversion of Control (IoC) because the framework is seen to be in control instead of the user application. This same thing is also done for the UI and networking parts of mobile phone applications.
MPI programs are like UI applications in that they can receive asynchronous messages, but without a framework to simplify the processing of events, the programmer must code the program to check for the receipt of incoming messages. Messages should be processed in the order in which they are received (there is limited buffering of incoming messages), forcing the application to be written with the added complexity of knowing what messages will arrive and potentially in which order.. Unfortunately, this means the MPI application that wants to communicate with another instance of itself running on another CPU or core must already be programmed to send and receive that message at the correct time between these two communicating instances. This makes traditional MPI programming more complex than writing UI applications and effectively limits their complexity.
The Proposed Framework
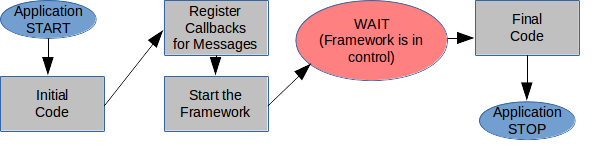
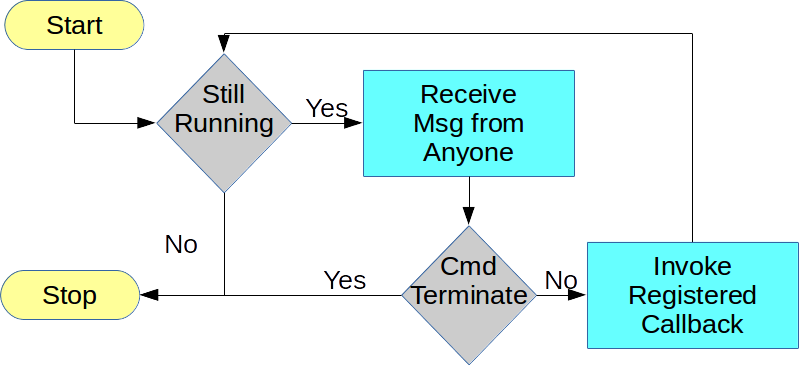
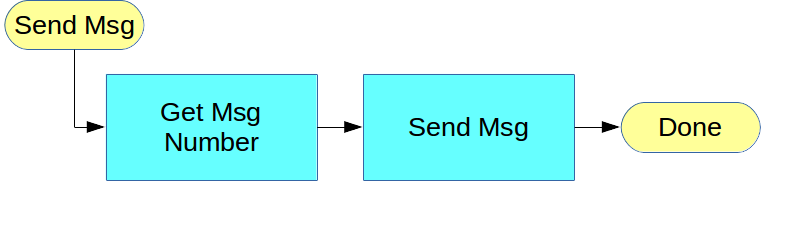
The framework suggested here is one that removes the complexity of the MPI communications from the user and places this in a separate layer to which the user application is linked or bound. The user application simply registers methods or functions (delegates) to be invoked when messages of specific types arrive (just as is done with UI frameworks -- see Figure 2) and then the application calls the start method of the framework and waits on the framework to notify it of incoming messages or events. The framework also provides the application with a method for sending one of the registered message types to another instance, and one for stopping the framework. This is all the application needs to know: it registers delegates for when certain message types arrive and then starts the framework and waits to process the received messages.
When the framework starts on any node it gathers the capabilities of the current CPU (network name, amount of memory available, number of cores, &c.) and sends this information to the control node (rank 0). This is depicted graphically in Figure 3. The application on the control node may use this information for determining how much memory is being shared between the instances on named CPUs, or for other purposes. When started on the control node, the framework also invokes any registered startup method of the user application.
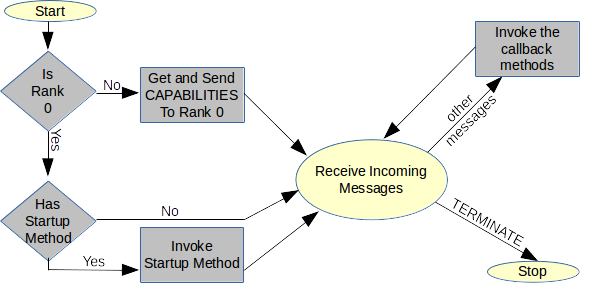
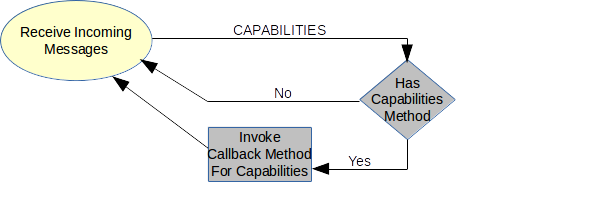
The startup method and the method to receive the capabilities are both optional parameters supplied to the framework on startup. Neither is required, but without one of them, the framework will sit idle until some other event starts the communications (from a separate thread, for instance.) When the capabilities message is received (see Figure 4), the registered method will be invoked and given the data and the number of the node which sent it.
The framework allows the user application to send any type of registered message to any instance at any time without any prior coordination. (pause and read that again) The only requirement is that both the sender and the receiver have registered a callback for this type of message. This removes much of the complexity of writing MPI applications, and it simplifies maintenance, but it also makes the application run faster as I will demonstrate.
Applications written this way are basically in a
WAIT
state until a message arrives. When the message arrives, the framework checks the message against its list of
registered callback methods, selects the appropriate one, and invokes it with the message and the rank of the sending
node as arguments. When that method is done, the framework waits for the receipt of the next message. When executing
one of these registered methods, the application may also send messages to any nodes.
The sequence of code that receives and processes this incoming message may be optimized or modified without changing other parts of the application. This allows the application code to be refactored to meet changing requirements or to improve the optimization.
A node may receive a message that contains work to be done, and when done it may send back a request for more work before returning control to the framework (as shown in Figure 7.) With this scenario and carefully allotted work details, the node doing the work may be kept busy and only given more work when it has completed its earlier quota - no other scheduling or work leveling may be required.
WORK_REQUEST
and
WORK
Messages
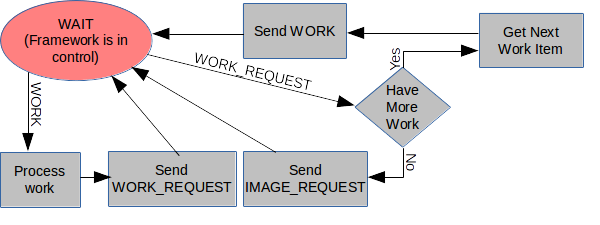

Using this framework means that the user application may be based around a very simple state machine as in Figures 7, 8, and 9. When
WORK
arrives, the registered method is invoked, and when done, the node sends a
WORK_REQUEST
back to the sender. When a node receives the
WORK_REQUEST
it may send the next bit of
WORK
to the source (see Figure 6). The very tight coupling of the application between nodes
and messages is all but eliminated, as each thread of execution based on the registered methods can be largely
implemented in isolation from the other threads of execution (see Figure 8).
IMAGE_REQUEST
and
IMAGE
Messages
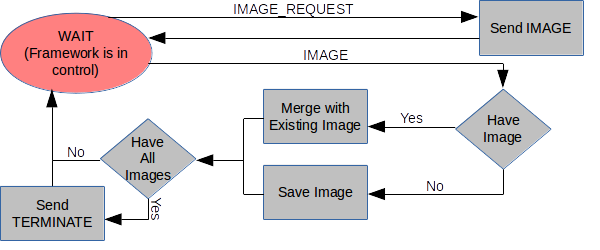
This allows the application to be split up into individual threads of execution based solely on the receipt of and required processing of messages. The user application no longer needs to be overly concerned about traditional communication rendezvous (as shown in Figure 1). This also allows an instance to perform any specific function, or even change overall function during the program execution. For instance, nodes may be selected for handling I/O operations and buffering based on their proximity to other nodes that will be using those services. An instance may designate an arbitrary number of nodes to a particular function simply by sending them the appropriate message - usually from the control node, which was initially supplied with the capabilities of all the nodes and can determine things like which nodes are on the same physical CPU or Blade.
The framework only needs to supply the following methods:
- init (required for C and Fortran, but implicit in the Python)
- register_method_for_message_type
- start
- send_message
- stop (only actioned from rank 0)
- finalize (required for C and Fortran, but implicit in Python)
The example framework also implements a broadcast_message, but unlike the standard
MPI_bcast
method which requires a rendezvous of all nodes, this simply sends the message to all the other nodes, which will
process it when they next enter the
WAIT
state.
Methods
Two applications were created to show the cost of sending the additional control messages between an arbitrary numbers of nodes, and to demonstrate the impact these have on throughput. The applications share most of their code, and only differ in how they handle the MPI communications: the first uses a traditional method of dividing the work into the number of available worker nodes, whereas the second sends work to the worker nodes on request.
These two test programs implement a very simple version of Kirchhoff 3D Time Migration; spreading randomly generated columns of data through an image volume. The columns of data are generated initially by the control node and distributed to the worker nodes. The algorithm spreads the data through the cube in circular fashion like expanding spheres from an (x,y) point on the surface. This migration algorithm was chosen because of the large amount of computation required at each worker node relative to the amount of data sent between the control node and the worker node. Less computationally intensive algorithms would tend to be more limited by I/O speed rather than by CPU performance.
The
TestDirect
application creates the worklist on the control node (rank 0) and then sends the data to the other nodes, resulting
in an even distribution of work. When all the work is distributed, the control node sends an empty packet of data to
each worker indicating all the data is distributed and the worker may begin processing the received work. This could
have been done with an MPI broadcast message as well. And after distributing all the work, the control node switches
to receiving the resultant images from the worker nodes. The received images are summed together to produce the final
image volume before the application terminates.
The
TestFramework
application creates the same worklist and sends one piece of work at a time to the worker nodes. When a worker node
is ready for more work it sends a
WORK_REQUEST
message to the control node and waits for the next column of data. When it receives this work it processes it and
asks for more work by sending another request back to the control node. This continues until no more work is
available, at which point the control node sends a request for the worker to send the result with the
IMAGE_REQUEST
message. It sums the individual image volumes the same as for the
TestDirect
application (as shown in Figure 8.)
The
TestFramework
operations are all centered on a
WAIT
state. The control node sends one piece of work to all the worker nodes to start the process going, and then it too
enters the
WAIT
state. If the node receives a column of data (the
WORK
message) it processes it, requests more work (
WORK_REQUEST
), and returns to the
WAIT
state. If the node receives a
WORK_REQUEST
it checks the list and either sends a column of data to the requesting node or sends a request for its image to be
returned to the control node (the
IMAGE_REQUEST
notice) if no more work is available, and then it enters the
WAIT
state. If the node receives a request for the image, it sends all pieces of the image back to the requesting node and
then enters the
WAIT
state. If the node receives the pieces of the image, it sums them into the final product, and if more work is still
being done, it enters the
WAIT
state; otherwise it sends the shut-down message to all the nodes.
Unlike the
TestDirect
application, the framework used in the
TestFramework
application sends a control or prefix message prior to the data message, and another control message as the
WORK_REQUEST
, as well as the control messages before each of the columns of data in the resultant image. This is two extra
messages for each data column for the worker to process and one extra for each of the resultant columns of the image
going back to the control node - almost twice as many messages as are used in the
TestDirect
application. These additional prefix messages were used in an earlier version of the framework instead of
using the
MPI_Probe
function. This was shown to not be necessary and the prefix messages were removed. Still, the additional
overhead of these messages was in itself revealing.
For instance, when the
TestDirect
processes 1000 columns of data on 16 nodes (15 worker nodes), there are 1015 total messages sent from the control
node to the workers, together with 800*12 messages (the example size used for these tests - 9600 columns in the
resultant image) from each of the 15 worker nodes (144,000 image columns) for a total of 145,015 individual MPI
messages. The
TestFramework
application sent the 1000 data columns together with 1000 control messages in response to the receipt of 985
WORK_REQUEST
messages. It also sent the 144,000 messages back to control but with an additional 144,000 control messages for a
total of 289,985 individual MPI messages. This is 145,015 messages versus 289,985. This is a non-trivial additional
amount of MPI messages for the
TestFramework
application (nearly twice the number of messages as used in the
TestDirect
application). Later versions of the framework eliminated these prefix messages.
If we wished to change the algorithm, the
TestDirect
application would be difficult to modify, probably requiring a complete rewrite of the main routine that sends and
receives the messages to add additional message types or other coordination messages. The
TestFramework
application could easily be modified to add additional message types together with whatever processing would be
required for these new messages by simply registering more methods to be invoked when the new messages are received,
and to add whatever code is required to generate the new messages. Since the application is being run from the
WAIT
state, the messages are not restricted to being generated or processed on any specific node (control or worker). And
the framework was modified to remove the additional messages without changing the
TestFramework
application.
Results
The two applications were each run on a desktop computer with a shared "home directory" on a business network. The applications made use of two machines referred to as "machine1" and "machine2". Each physical machine has 8 (SMP cores for a total of 16. Both machines were running the Ubuntu 14.04 LTS Operating System. For these tests, the applications were started on "machine1" with this command:
time; mpiexec -n 16 -host machine1,machine2 TestXXX.py
This mpiexec command spreads the application across the two machines with 8 instances on each machine for one instance per core. These applications were run in isolation, in competition with each other, and in competition with another MPI application that was only running on one of the machines. The resultant execution times were recorded for each of these scenarios to make the following graphs.
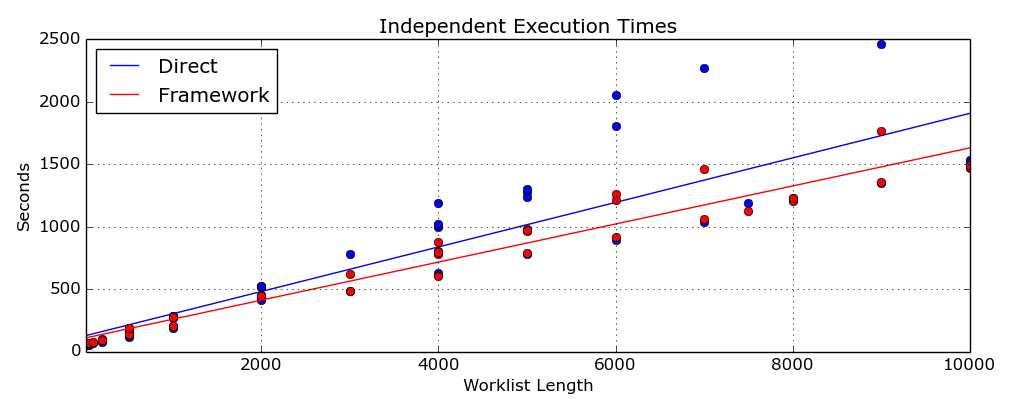
This first figure here (Figure 10) shows the execution times for the applications running
independently. In the absence of any appreciable competition for resources, the
TestFramework
application is significantly faster than the
TestDirect
for worklist lengths in excess of 1000. This is because the
TestDirect
application, despite using fewer MPI messages, doesn't allow for differences in communication speed between nodes on
the same CPU and nodes across the network. MPI is extremely fast in sending messages between nodes on the same
machine, but significantly slower when sending messages between different networked computers. The
TestFramework
application naturally adjusts itself on each node because each node requests work when it's ready for more. It also
caters for different processing speeds and network capabilities, which is completely absent from the
TestDirect
worklist division.
These tests were all run on the same two machines, and the variability is likely due to other network traffic or occasional use of the hardware by other system users. The tests for each worklist length were run consecutively to avoid differences associated with network use at different times of the day. Many of the tests were run on weekends, evenings, and very early mornings to avoid interference from others using the business network.
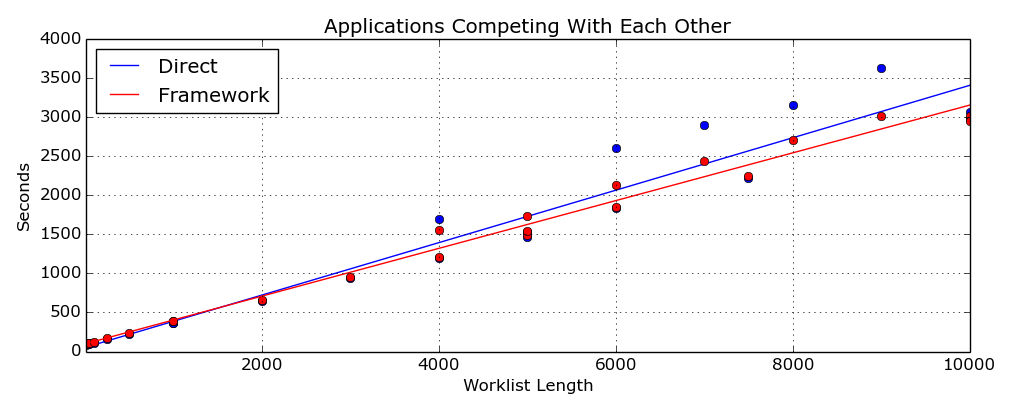
This second figure (Figure 11) shows the execution times for the applications running at
the same time and competing for resources. In this case, the
TestDirect
has a slight advantage because once the work is distributed, it does fewer operations that might cause the Operating
System to do a context switch in its "fairness" algorithm and switch to running the other application. This advantage
is very slight but noticeable for short worklists - see where the execution time for the framework is greater than
that for the direct method. For larger worklists the
TestFramework
is surprisingly and consistently faster.
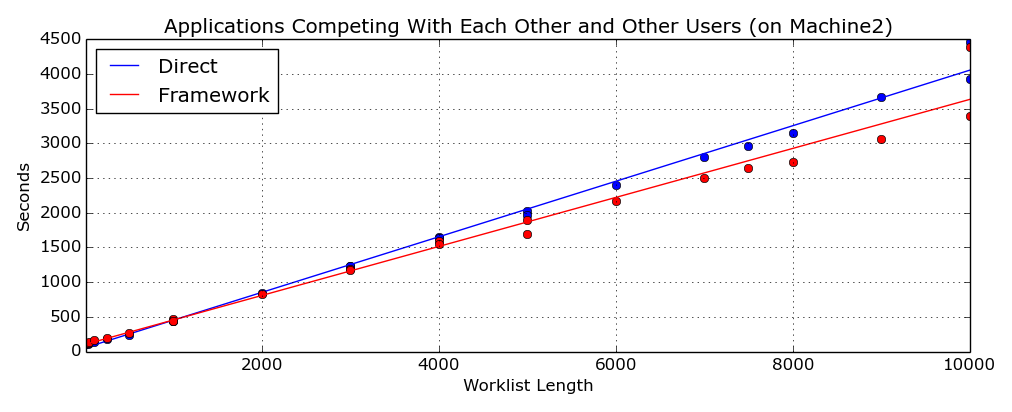
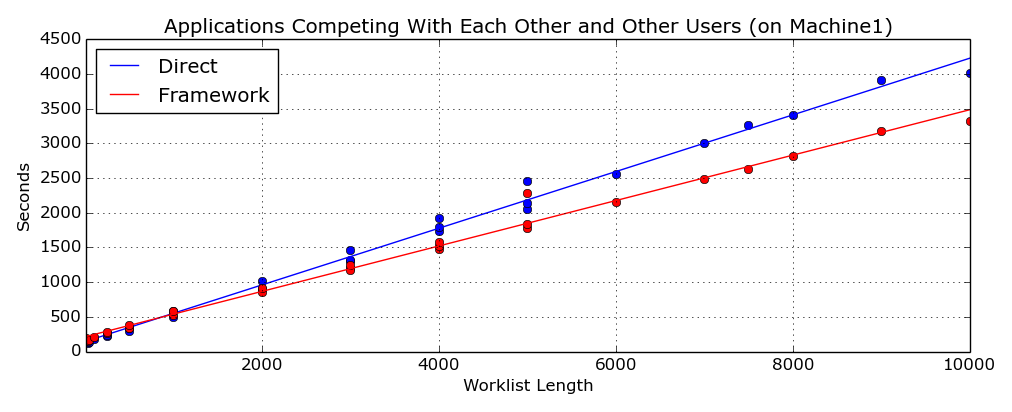
These two figures (Figure 12 and Figure 13) show the
execution times for the applications running at the same time and competing with a third application (another copy of
the
TestDirect
program) which is running on only one of the two machines. The top one has the extra application on "Machine2" and
the lower has it on "Machine1”. The
TestFramework
successfully caters for resource contention on the available network and has a much better throughput than the
TestDirect
which has no mechanism for redistributing the workload. And this difference becomes more noticeable as the amount of
work increases.
Short Discussion and Conclusion
This work demonstrates the similarities between UI events and the receipt of MPI messages. It shows how this similarity naturally leads to the construction of a framework or layer to abstract the complexity of the MPI primitives and communications (much as is done for UI frameworks monitoring signals and events), and how an MPI application can be designed simply and executed efficiently in a heterogeneous environment that may be shared with other processes that may degrade the performance of MPI applications designed using traditional methods. This framework-based method allows the application to grow in complexity with additional message types and distributed functionality, opening up the use of MPI on networked desktop machines or clusters for solving a large variety of problems. The framework approach simplifies the construction of MPI applications in the same manner as UI frameworks simplify the construction of desktop or mobile applications.
Sources
The code is available on request, though it's rather old by now (if I can still find it ;-).
This paper is an original work and not an extension of other models or papers.